There is a great site of labs by Oracle - LiveLabs. They are using OCI (Oracle Cloud Infrastructure). One of the labs, named "Build AI-Powered Image Search into your Oracle APEX App" is combining APEX with AI - Vision Service and uses the Analyze_Image option of the service. I wanted to combine APEX with a different flavor of the AI Service - Text_Detection, to extract words and codes from images. Text Detection is available both as part of AI-Document Service and AI-Vision Service. For various reasons (laziness) I preferred to use the AI-Vision option by making small modifications to the LiveLabs lab.
The post bellow has 3 parts:
- The short technical part that explains modifications to the original lab to turn it into Text_Detection, from Image_Classification.
- Me summarizing the lab, doin some explantaions to myself about the code they used and how to modify it to Text_Detection.
- Sample JSON result of Image_Classification and Text_Detection.
You might also want to check the follow up post: Implementing the post - Adding AI - Vision Service, Text Detection to APEX.
You might also want to check the post: Adding AI - Vision Service, Object Detection to APEX
This is the "readers digest" part, if you only want the code.
In the next section I will try to explain to myself what the Lab did and how&why to modify it, to get to the same results. If you only want the changes in the code comparing to the lab, this section is for you.
Basically, follow the Lab precisely until Lab 3 / Task 2: Invoke the OCI Vision REST Data Source through a Page Process.
Only if you want to control the language parameter of the service... In Lab 3/ Task 1/ Step 10, change the language value in the bellow JSON from "ENG" to you preferred language from
the list (didn't test it myself, I'm fine with the default).
{
"compartmentId": "#COMPARTMENT_ID#",
"image": {
"source": "INLINE",
"data": "#FILE_DATA#"
},
"features": [
{
"featureType": "#FEATURE_TYPE#",
"language": "ENG"
}
]
}
In LAB 3, Task 2 - Invoke the OCI Vision REST Data Source through a Page Process, step 10 change to:
Click FEATURE_TYPE and enter the following (we replace the IMAGE_CLASSIFICATION value):
Under Value :
Type: Static Value
Value: TEXT_DETECTION
In LAB 3, Task 2 - Invoke the OCI Vision REST Data Source through a Page Process, step 14 change the PL/SQL Code to one of the 2 options (in the "Parse the Response" part).
For Word based text_detection use:
UPDATE SM_POSTS
SET
AI_OUTPUT = (
SELECT
LISTAGG(obj_name, ',') WITHIN GROUP(
ORDER BY
obj_name
)
FROM
JSON_TABLE ( :P1_RESPONSE, '$.imageText.words[*]'
COLUMNS
obj_name VARCHAR2 ( 100 ) PATH '$.text[*]'
)
)
WHERE
ID = :P1_ID;
For Lines based text_detection use:
UPDATE SM_POSTS
SET
AI_OUTPUT = (
SELECT
LISTAGG(obj_name, ',') WITHIN GROUP(
ORDER BY
obj_name
)
FROM
JSON_TABLE ( :P1_RESPONSE, '$.imageText.lines[*]'
COLUMNS
obj_name VARCHAR2 ( 100 ) PATH '$.text[*]'
)
)
WHERE
ID = :P1_ID;
Why? Because the text detection returns 2 sets of texts. One is based on separate words it identifies and the other on lines. Pick your choice. (In the image bellow I used Page 2, so it's P2 instead of P1):
Bonus
I wanted the data slightly differently. Not as a one text
string, separated by commas. I want them as rows in a new table
(SM_POSTS_STRS) with columns ID (Number) and extracted_Text (varchar2(100)). I created the table and changed the LAB 3, Task 2 - Invoke the OCI Vision REST Data Source through a Page Process, step 14, PL/SQL Cod, to the following:
INSERT INTO SM_POSTS_STRS (ID, extracted_Text)
SELECT
:P2_ID, obj_name
FROM
JSON_TABLE ( :P2_RESPONSE, '$.imageText.lines[*]'
COLUMNS
obj_name VARCHAR2 ( 100 ) PATH '$.text[*]'
)
;
Again, you can pick your choice (lines or words).
I will explain the LiveLabs lab to myself first.
From here, I summarize the lab instructions and add remarks to myself.
First, LAB 1 is creating the Web Credentials, using the API Keys. I only summarize here the lab instructions. Please see it in the LAB, it's better there and has pictures and free. This part is standard to most OCI services you will use in APEX. You can skip to Lab 3.
1. In OCI Account, Click on the Profile icon at the top-right corner and select your Profile hyperlink.
2. Under Resources section at the bottom-left, select API Keys and then click Add API Key.
3. Select Generate API Key Pair and click Download Private Key. Save the file.
4. Click Add. The key is added, and the Configuration File Preview is displayed. Copy and save it in additional file.
5. In APEX go to App Builder -> Workspace Utilities -> Web Credentials and click Create.
6. All the content you need is in those 2 files you saved. The labs says to fill the following and Save:
Name: apex_ai_cred
Authentication Type: Oracle Cloud Infrastructure (OCI)
OCI User ID: Enter the OCID of the Oracle Cloud
user Account. You can find the OCID in the Configuration File Preview
generated during the API Key creation.
OCI Private Key: Open the private key (.pem file) downloaded in the previous task. Copy and paste the API Key.
Now we have Web Credentials named "apex_ai_cred".
Lab 2 imports and modifies existing APEX App. Things get interesting in Lab 3.
Task 1 here is to Configure OCI Vision REST API as REST Data Source
1. In the application home page click Shared Components -> REST Data Sources -> Create. Select From scratch and click Next.
2. In Lab 3/ Task 1/ Step 5, it says:
Under Create REST Data Source, enter the following attributes and click Next.
Note: URL Endpoint may differ based on your OCI tenancy. Refer to the following link for more details- https://docs.oracle.com/en-us/iaas/api/#/en/vision/20220125
BREAK
What is the AnalyzeImage action? Lets take a break from the lab and dive in:
Under Vision API, we have AnalyzeImage here.

It has 2 parameters: opc-request-id (header string, not required) and Body, described here.
The Body has 3 Atrributes: compartmentId, features (documented here) and image (ImageDetails here).
Features have a required featureType:
In the Lab itself they used the IMAGE_CLASSIFICATION option (LAB 3 / Task 3/ step 10).
I, on the other hand, would like yo use TEXT_DETECTION featureType.
Good news: I can leave the REST API configuration as it is in the lab and update only later, in APEX UI the featureType.
While ImageClassificationFeature Reference has 3 Attributes:
- above mentioned featureType-
IMAGE_CLASSIFICATION - maxResults (The maximum number of results to return, not required, deafault 5)
- modelId (For custom models, use the custom model ID here. When null or absent, the default generic model will be used)
For ImageTextDetectionFeature Reference we have only 2 Atributes
- above mentioned featureType -
TEXT_DETECTION - language - not required, see the list here
The imageDetails has one attribute - source that can be:
INLINE: The data is included directly in the request payload.OBJECT_STORAGE: The image is in OCI Object Storage.
the lab uses the Inline option. In this case we also have the data attribute (raw Image data).
So we are back to the Lab,I'll repeat step 2 where we stopped:
2. In Lab 3/ Task 1/ Step 5 we continue wit REst Data Source creation. As data Source type we are guided to select "Oracle Cloud Infrastructure (OCI)"
Under Create REST Data Source, enter the following attributes and click Next.
Note: URL Endpoint may differ based on your OCI tenancy. Refer to the following link for more details- https://docs.oracle.com/en-us/iaas/api/#/en/vision/20220125
3. Under Create REST Data Source - Remote Server, click Next and Under Authentication, set Authentication Required button to ON. In Credetials, select the previously created apex_ai_cred.
4. Click REST Source Manually.
REST data source is successfully created. The next step to configure the POST operation parameters for this REST Data Source.
5. On the REST Data Sources page, click OCI Vision. Select Operations Tab and click Edit icon for the POST operation and enter the following:
{
"compartmentId": "#COMPARTMENT_ID#",
"image": {
"source": "INLINE",
"data": "#FILE_DATA#"
},
"features": [
{
"featureType": "#FEATURE_TYPE#",
"maxResults": 5
}
]
}
If we get back to the API documentation we have seen before, in this JSON we have 3 attributes (compartmentId, image and features).
For InlineImageDetails we have source and data, I'm happy with it as is.
For ImageClassificationFeature the JSON has featureType and maxResults (and no modelId). I wanted the ImageTextDetectionFeature while the above should work, the following JSON might be more fitting this need:
{
"compartmentId": "#COMPARTMENT_ID#",
"image": {
"source": "INLINE",
"data": "#FILE_DATA#"
},
"features": [
{
"featureType": "#FEATURE_TYPE#",
}
]
}
If you prefer you can add a language (didn't test it myself, since I prefer the default.)
{
"compartmentId": "#COMPARTMENT_ID#",
"image": {
"source": "INLINE",
"data": "#FILE_DATA#"
},
"features": [
{
"featureType": "#FEATURE_TYPE#",
"language": "ENG"
}
]
}
6. Once we a done with the JSON, lets get back to the LAB, Task 2 - point 11 - Under Operation Parameters, click Add Parameter. I'm fine with the rest of the Task...
7. In the Edit REST Data Source Parameter wizard, add the following 5 parameters one after the other (COMPARTMENT_ID, FILE_DATA, FEATURE_TYPE, RESPONSE, Content-Type):
8. Click
Apply Changes. Now we are done with Vision REST API configuration as Data Source. If you are using it in more than one APP, repeat for each (where you can create it as copy from the first definition).
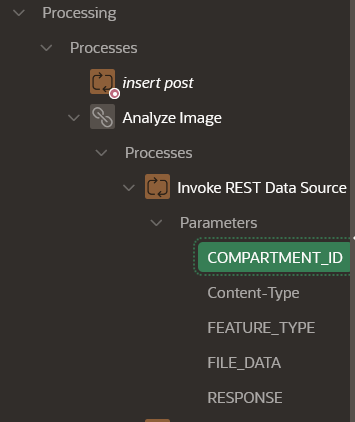
In Lab 3 / Task 2: Invoke the OCI Vision REST Data Source through a Page Process we apply the recently created Rest Data Source, with a specific APEX App.
In the App iself we have an "Add Post" option
When pressed we get this window:
In the Lab (Task 2/ point 3) we make changed on the Body of that page (Timeline)
1. On Timeline - Create Page Item (right click). Name created Page Item P1_RESPONSE, and set the Type to Hidden. Now we have P1_RESPONSE under Timeline Region Body. Now we move to Processing Tab (top left, third):
2. Create a process by pressing right Click on "Processing" and Create Process. On the right part of screen, Under Identification, Name it Analyze Image and set the type as Execution Chain. Under Settings:
Enable
Run in Background.
What is Execution Chain? It is a Page process type. It can execute a sequence of page
processes, either in the foreground or in the background..In our case it is the background.
3. Now we are getting to the Invoke REST Data Sourcewe created previously.
Right click on the Analyze Image Process and select Add Child Process.
In the Property Editor, enter the following:
Under Identification section:
Under Settings Section:
Type: REST Source
REST Source: OCI Vision
Operation: POST
To remind you, we defined in the OCI Vision, Rest Source, in the Post Operation 5 parameters, 4 of them of the Type "Request or Response Body".
Now we get them as parameters.
For
COMPARTMENT_ID, under Value we set the type as Static Value and enter the Compartment ID we got in the "Configuration File Preview" at the begining.
For FEATURE_TYPE we want to make some modifications. In the Lab it states: under Value we set the type as Static Value and set Value as IMAGE_CLASSIFICATION. We on the other hand want the Value to be TEXT_DETECTION.
For
FILE_DATA Under Value:
select replace(replace(apex_web_service.blob2clobbase64(file_blob), chr(10),''),chr(13),'')
from SM_posts
where ID = :P1_ID;
This actuall removes the Carrige Return Line Feed from the image file. Where the function blob2clobbase64 is used to convert a BLOB datatype into a CLOB that is base64 encoded.
For RESPONSE we Disable Ignore Output under Parameter and select the in the Value/Item P1_RESPONSE from Current Page items.
4. Right click on the Analyze Image process and select Add Child Process.
In the Property Editor, enter the following:
Under Identification :
- For Name : Parse the Response
Under Source:
- For PL/SQL Code : Copy and paste the below code in the PL/SQL Code editor:
UPDATE SM_POSTS
SET
AI_OUTPUT = (
SELECT
LISTAGG(obj_name, ',') WITHIN GROUP(
ORDER BY
obj_name
)
FROM
JSON_TABLE ( :P1_RESPONSE, '$.labels[*]'
COLUMNS
obj_name VARCHAR2 ( 100 ) PATH '$.name[*]'
)
)
WHERE
ID = :P1_ID;
Since the Text JSON resonce file is differant, we will have to change the SQL CODE to this:
For Word based text_detection use:
UPDATE SM_POSTS
SET
AI_OUTPUT = (
SELECT
LISTAGG(obj_name, ',') WITHIN GROUP(
ORDER BY
obj_name
)
FROM
JSON_TABLE ( :P2_RESPONSE, '$.imageText.words[*]'
COLUMNS
obj_name VARCHAR2 ( 100 ) PATH '$.text[*]'
)
)
WHERE
ID = :P1_ID;
For Lines based text_detection use:
UPDATE SM_POSTS
SET
AI_OUTPUT = (
SELECT
LISTAGG(obj_name, ',') WITHIN GROUP(
ORDER BY
obj_name
)
FROM
JSON_TABLE ( :P2_RESPONSE, '$.imageText.lines[*]'
COLUMNS
obj_name VARCHAR2 ( 100 ) PATH '$.text[*]'
)
)
WHERE
ID = :P1_ID;
Now click Save.
Why? Because the text detection returns 2 sets of extracted texts. One is based on seperate words it identifies and the other on lines. Pick your choice. See the example at the end of te post.
Now lets understand the SQL code.
LISTAGG - For a specified measure, LISTAGG orders data within each group specified in the ORDER BY clause and then concatenates the values of the measure column.
In this case the LISTAGG creates a list of values returned from the JSON file, seperated by commas and ordered by the name.
I wanted the data slightly diferently. Not as a one text string,separated by commas. I want them as rows in a new table (ST_POSTS_STRS) with columns ID (Number) and extracted_Text (varchar2).
INSERT INTO SM_POSTS_STRS (ID, extracted_Text)
SELECT
:P1_ID, obj_name
FROM
JSON_TABLE ( :P2_RESPONSE, '$.imageText.lines[*]'
COLUMNS
obj_name VARCHAR2 ( 100 ) PATH '$.text[*]'
)
)
;
The rest of the LAB is standard APEX.
JSON Result Examples
IMAGE_CLASSIFICATION JSON result
{
"labels": [
{
"name": "Overhead power line",
"confidence": 0.9933029
},
{
"name": "Road",
"confidence": 0.99322593
},
{
"name": "Transmission tower",
"confidence": 0.99315405
},
{
"name": "Vegetation",
"confidence": 0.99306077
},
{
"name": "Electrical supply",
"confidence": 0.99297935
}
],
"ontologyClasses": [
{
"name": "Road",
"parentNames": [],
"synonymNames": []
},
{
"name": "Overhead power line",
"parentNames": [],
"synonymNames": []
},
{
"name": "Vegetation",
"parentNames": [
"Plant"
],
"synonymNames": []
},
{
"name": "Transmission tower",
"parentNames": [],
"synonymNames": []
},
{
"name": "Electrical supply",
"parentNames": [],
"synonymNames": []
},
{
"name": "Plant",
"parentNames": [],
"synonymNames": []
}
],
"imageClassificationModelVersion": "1.5.97",
"errors": []
}
TEXT_DETECTION JSON Result
{
"ontologyClasses": [],
"imageText": {
"words": [
{
"text": "INTERSTATE",
"confidence": 0.98098326,
"boundingPolygon": {
"normalizedVertices": [
{
"x": 0.2132034632034632,
"y": 0.21575342465753425
},
{
"x": 0.37445887445887444,
"y": 0.2100456621004566
},
{
"x": 0.37554112554112556,
"y": 0.2557077625570776
},
{
"x": 0.21428571428571427,
"y": 0.2614155251141553
}
]
}
},
{
"text": "SOUTH",
"confidence": 0.98742044,
"boundingPolygon": {
"normalizedVertices": [
{
"x": 0.4556277056277056,
"y": 0.19863013698630136
},
{
"x": 0.8409090909090909,
"y": 0.19863013698630136
},
{
"x": 0.8409090909090909,
"y": 0.295662100456621
},
{
"x": 0.4556277056277056,
"y": 0.295662100456621
}
]
}
},
{
"text": "215",
"confidence": 0.963077,
"boundingPolygon": {
"normalizedVertices": [
{
"x": 0.2077922077922078,
"y": 0.24771689497716895
},
{
"x": 0.3961038961038961,
"y": 0.24771689497716895
},
{
"x": 0.3961038961038961,
"y": 0.3744292237442922
},
{
"x": 0.2077922077922078,
"y": 0.3744292237442922
}
]
}
},
{
"text": "Belt",
"confidence": 0.9743079,
"boundingPolygon": {
"normalizedVertices": [
{
"x": 0.12229437229437229,
"y": 0.519406392694064
},
{
"x": 0.4025974025974026,
"y": 0.519406392694064
},
{
"x": 0.4025974025974026,
"y": 0.6244292237442922
},
{
"x": 0.12229437229437229,
"y": 0.6244292237442922
}
]
}
},
{
"text": "Route",
"confidence": 0.9743079,
"boundingPolygon": {
"normalizedVertices": [
{
"x": 0.47835497835497837,
"y": 0.519406392694064
},
{
"x": 0.9004329004329005,
"y": 0.519406392694064
},
{
"x": 0.9004329004329005,
"y": 0.6244292237442922
},
{
"x": 0.47835497835497837,
"y": 0.6244292237442922
}
]
}
}
],
"lines": [
{
"text": "INTERSTATE",
"confidence": 0.98098326,
"boundingPolygon": {
"normalizedVertices": [
{
"x": 0.2132034632034632,
"y": 0.21575342465753425
},
{
"x": 0.37445887445887444,
"y": 0.2100456621004566
},
{
"x": 0.37554112554112556,
"y": 0.2557077625570776
},
{
"x": 0.21428571428571427,
"y": 0.2614155251141553
}
]
},
"wordIndexes": [
0
]
},
{
"text": "SOUTH",
"confidence": 0.98742044,
"boundingPolygon": {
"normalizedVertices": [
{
"x": 0.4556277056277056,
"y": 0.19863013698630136
},
{
"x": 0.8409090909090909,
"y": 0.19863013698630136
},
{
"x": 0.8409090909090909,
"y": 0.295662100456621
},
{
"x": 0.4556277056277056,
"y": 0.295662100456621
}
]
},
"wordIndexes": [
1
]
},
{
"text": "215",
"confidence": 0.963077,
"boundingPolygon": {
"normalizedVertices": [
{
"x": 0.2077922077922078,
"y": 0.24771689497716895
},
{
"x": 0.3961038961038961,
"y": 0.24771689497716895
},
{
"x": 0.3961038961038961,
"y": 0.3744292237442922
},
{
"x": 0.2077922077922078,
"y": 0.3744292237442922
}
]
},
"wordIndexes": [
2
]
},
{
"text": "Belt Route",
"confidence": 0.9743079,
"boundingPolygon": {
"normalizedVertices": [
{
"x": 0.12229437229437229,
"y": 0.519406392694064
},
{
"x": 0.9015151515151515,
"y": 0.519406392694064
},
{
"x": 0.9015151515151515,
"y": 0.6255707762557078
},
{
"x": 0.12229437229437229,
"y": 0.6255707762557078
}
]
},
"wordIndexes": [
3,
4
]
}
]
},
"textDetectionModelVersion": "1.6.221",
"errors": []
}