This is the seventh part of OBIEE 12c Advanced Analytic:
The EVALUATE_SCRIPT function, like the rest of Evaluate family, helps us to call content external to OBIEE. In this case the function is not Database function, it is R script.
Since R is based on such packages, and they are free to download (https://cran.r-project.org/), modify and develop, this is a great bonus.( I have no intention guiding here about the R packages in general.)
Actually, the great post by Antony Heljula, at Peak Indicators blog, Performing Real-Time Sentiment Analysis in Oracle BI 12c | Peak Indicators, made my post mostly redundant.
I will cover here just few very technical aspects.
Oracle documentation describes the syntax of this function.
If you have seen the other R based functions syntax, you shouldn't be surprised here.
The big question is what is that mysterious "filerepo//"? The location of the "filerepo" is:
[Installation_Home]/user_projects/domains/bi/bidata/components/OBIS/advanced_analytics/script_repository
(In my personal case, OBIEE 12c installed in D\MWHOME12, so it's:
D:\MWHOME12\user_projects\domains\bi\bidata\components\OBIS\advanced_analytics\script_repository).
Checking the location will reveal the connection to R based script that I talked about in the previous posts:

So if you insist, the following 2 uses of outlier are equivalent:
- OBIEE 12c Advanced Analytics Functions part 1. Introduction & Trendline
- OBIEE 12c Advanced Analytic part 2: BIN and WIDTH_BUCKET
- OBIEE 12c Advanced Analytic part 3: Forecast
- OBIEE 12c Advanced Analytic part 4: Cluster
- OBIEE 12c Advanced Analytic part 5: Outlier
- OBIEE 12c Advanced Analytic part 6: Regression
- OBIEE 12c Advanced Analytic part 7: EVALUATE_SCRIPT (this one)
The EVALUATE_SCRIPT function, like the rest of Evaluate family, helps us to call content external to OBIEE. In this case the function is not Database function, it is R script.
Since R is based on such packages, and they are free to download (https://cran.r-project.org/), modify and develop, this is a great bonus.( I have no intention guiding here about the R packages in general.)
Actually, the great post by Antony Heljula, at Peak Indicators blog, Performing Real-Time Sentiment Analysis in Oracle BI 12c | Peak Indicators, made my post mostly redundant.
I will cover here just few very technical aspects.
Oracle documentation describes the syntax of this function.
Syntax
EVALUATE_SCRIPT( <script_file_path>, <column_name>, <options>, [<runtime_binded_column_options>] )Where:
script_file_path indicates the script XML file path. For example, filerepo//obiee.TimeSeriesForecast.xml.column_name indicates the column name upon which to forecast.options
is a string list of names or value pairs separated by a semi-colon (;).
For example,
'algorithm=GLM;CustomerID=%1;ActualRevenue=%2;YearsAsCustomer=%3',runtime_binded_column_options indicates an optional variable list of column expression. You can specify one or more columns.If you have seen the other R based functions syntax, you shouldn't be surprised here.
The big question is what is that mysterious "filerepo//"? The location of the "filerepo" is:
[Installation_Home]/user_projects/domains/bi/bidata/components/OBIS/advanced_analytics/script_repository
(In my personal case, OBIEE 12c installed in D\MWHOME12, so it's:
D:\MWHOME12\user_projects\domains\bi\bidata\components\OBIS\advanced_analytics\script_repository).
Checking the location will reveal the connection to R based script that I talked about in the previous posts:
So if you insist, the following 2 uses of outlier are equivalent:
EVALUATE_SCRIPT('filerepo://obiee.Outliers.xml', 'isOutlier', 'algorithm=mvoutlier;id=%1;arg1=%2;arg2=%3;useRandomSeed=False;', "Products"."Product Number", "Base Facts"."Revenue", "Base Facts"."Billed Quantity")
OUTLIER(( "Products"."Product Number"), ("Base Facts"."Revenue", "Base Facts"."Billed Quantity"), 'isOutlier','')
That happens in an analysis with columns Product Number, Revenue and Billed Quantity.

Our examples were with Company, Product Type, Revenue and Billed Quantity in the analysis. It creates slightly more interesting option is the following couple, that returns the same results:
OUTLIER(( "Offices"."Company", "Products"."Product Type"), ("Base Facts"."Revenue", "Base Facts"."Billed Quantity"), 'isOutlier','')
EVALUATE_SCRIPT('filerepo://obiee.Outliers.xml', 'isOutlier', 'algorithm=mvoutlier;id=%1; arg1=%2;arg2=%3;useRandomSeed=False;', "Offices"."Company"||"Products"."Product Type", "Base Facts"."Revenue", "Base Facts"."Billed Quantity")
Please note I had to use both Company and Product Type combination as ID. OBIEE does it for us automatically.

But what happens if I add a column (Year in our case) that is not in the outlier functions?
I have different result from the outlier function and the Evaluate_script one! That is because OBIEE automatically adds those columns as partitionByDimension. You can have up to 5 of those.
So we have the same outlier function as in the previous example with different results.
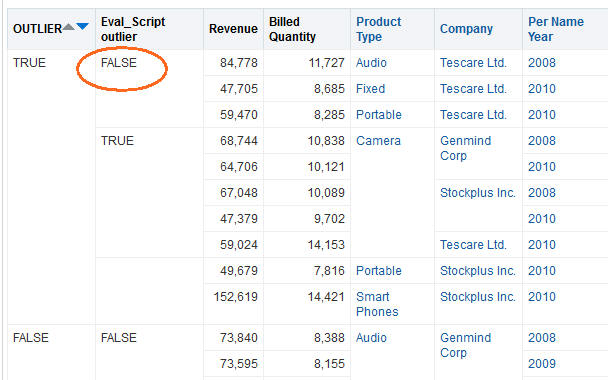
The correct EVAUATE_SCRIPT syntax now is:
EVALUATE_SCRIPT('filerepo://obiee.Outliers.xml', 'isOutlier', 'algorithm=mvoutlier;id=%1; partitionByDimension1=%2;arg1=%3;arg2=%4;useRandomSeed=False;', "Offices"."Company"||"Products"."Product Type","Time"."Per Name Year", "Base Facts"."Revenue", "Base Facts"."Billed Quantity")
Now the results are the same:

I didn't find formal Oracle documentation about the XML files structure. From the existing files we can see the general format of:
- inputs columns, those can be dimensions or other, with the relevant attributes for each such as name, sortorder, nilable, required...
- outputs columns with attribute such as name, datatype(integer, double, varchar(20)...), aggr_rule...
- options (I suspect that even if they aren't any, you should have this part)
- scriptcontent - the actual function in the format: function(dat, OPTION_COLUMNS) { library(THE_LIBRARY) df <- THE_ACTUAL_CODE_WITH_PARAMETERS return (df) }
No comments:
Post a Comment